Reinforce is one of my favorite algorithms in machine learning. It’s useful for reinforcement learning.
The formal goal of reinforce is to maximize an expectation, 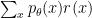
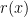
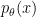
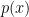
This is the case because of the following simple bit of math:
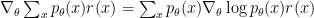
which clearly shows that to estimate the gradient wrt the expected reward, we merely need to sample from 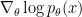
Reinforce is so tantalizing because sampling from a distribution is very easy. For example, the distribution 
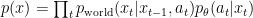
and only part of 
Similarly,
So reinforce is dead easy to apply: for example, it could be applied to a robot’s policy. To sample from our distribution, we’d run the policy, get the robot to interact with our world, and collect our reward. And we’ll get an unbiased estimate of the gradient, and presto: we’d be doing stochastic gradient descent on the policy’s parameters.
Unfortunately, this simple approach is not so easy to apply. The problem lies in the huge variance of our estimator 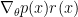
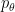
(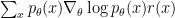
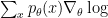


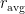
To paraphrase, reinforce adds a small perturbation to the choices and sees if the total reward has improved. If we’re trying to do something akin to supervised learning with reinforce with a small label set, then reinforce won’t do so terribly: each action would be a classification, and we’d have a decent chance to guess the correct answer. So we’ll be guessing the correct answer quite often, which will supply our neural net with training signal, and learning will succeed.
However, it’s completely hopeless to train a system that makes a large number of decisions with a tiny reward in the end.
On a more optimistic note, large companies that deploy millions of robots could refine their robot’s policies with large scale reinforce. During the day, the robots will collect the data for the policy, and during the night, the policy will be updated.
