Deep neural networks have enjoyed a fair bit of success in speech recognition and computer vision. The same basic approach was used for both problems: use supervised learning with a large number of labelled examples to train a big, deep network to solve the problem. This approach just works whenever the solution to the problem that we seek to solve can be represented with a deep neural network, which is often the case for reasons that I will not explain here.
But there is another way. Unsupervised learning is the idea that we can understand how the world “works” by simply passively observing it and building a rich internal mental model of it. This way, when we have a supervised learning task we wish to solve, we can consult the mental model that was learned during the unsupervised learning stage, and solve the problem much more rapidly, without using as many labels. Unsupervised learning is very appealing, because it doesn’t require any labels. Imagine: you simply get a system to observe the world for a while, and after a while we could use it to answer difficult questions about the signal — such as to determine what objects are in an image, what are their 3D shapes, and and what are their poses.
But so far there are no state of the art results that benefit use unsupervised learning. Why?
1: We don’t have the right unsupervised learning algorithm: Supervised learning algorithms work well because they directly optimize the performance measure that we care about and come with a guarantee: if the neural network is big enough and is trained on enough labelled data, the problem will be completely and utterly solved. In contrast, unsupervised learning algorithms do not have such a guarantee. Even if we used the best current unsupervised learning algorithm, and trained it on a huge neural net with a huge amount of data, we could not be confident that it would help us build high-performing systems.
2: Whatever the unsupervised learning algorithm will do, it will necessarily be different from the objective that we care about. As the unsupervised learning algorithm doesn’t know about what the desired objective is, the only thing it can do is to try and understand as much of the signal as possible, in order to, hopefully, understand the relevant bits about the problem we care about. Thus, if it takes a big network to do really well the purely supervised problem (as is the case —- the high-performing supervised nets have 50M parameters, and they’re still growing), where all the network’s resources are dedicated to the task, it will take a much larger network to really benefit from unsupervised learning, since it attempts to solve a much harder problem that includes our supervised objective as a special case.
Thus, at this point, it is simply not clear how and why will the future unsupervised learning algorithms work.
 (from http://www.kip.uni-heidelberg.de/cms/vision/projects/recent_projects/hardware_perceptron_systems/image_recognition_with_hardware_neural_networks/)
(from http://www.kip.uni-heidelberg.de/cms/vision/projects/recent_projects/hardware_perceptron_systems/image_recognition_with_hardware_neural_networks/)

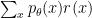 , where
, where 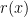 is the reward function and
is the reward function and 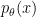 is a distribution. To apply reinforce, all we need is to be able to sample from
is a distribution. To apply reinforce, all we need is to be able to sample from 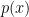 and to evaluate the reward
and to evaluate the reward 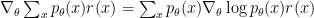
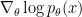 by the reward
by the reward  could be the sequence of states and actions chosen by our policy and the environment, so
could be the sequence of states and actions chosen by our policy and the environment, so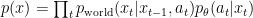 ,
, .
.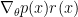 . It is easy to see, intuitively, where this variance comes from. Reinforce obtains its learning signal from the noise in its policy distribution
. It is easy to see, intuitively, where this variance comes from. Reinforce obtains its learning signal from the noise in its policy distribution 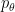 . In effect, reinforce makes a large number of random choices through the randomness in its policy distribution, and if they do better than average, then we’ll change our parameters so that these choices are more likely in the future. Similarly, if the random choices end up doing worse than random, the model will try to avoid choosing this specific configuration of actions.
. In effect, reinforce makes a large number of random choices through the randomness in its policy distribution, and if they do better than average, then we’ll change our parameters so that these choices are more likely in the future. Similarly, if the random choices end up doing worse than random, the model will try to avoid choosing this specific configuration of actions.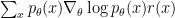 =
= 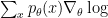
 because
because  . There is a simple formula for choosing the optimal
. There is a simple formula for choosing the optimal 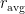 ).
).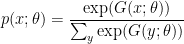
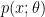 so that the average log probability of the data distribution
so that the average log probability of the data distribution ![E_{x\sim D(x)} [ \log p(x;\theta) ]](https://s0.wp.com/latex.php?latex=E_%7Bx%5Csim+D%28x%29%7D+%5B+%5Clog+p%28x%3B%5Ctheta%29+%5D&bg=ffffff&fg=000&s=0&c=20201002) is as large as possible.
is as large as possible.![E_{x\sim D(x)}[\nabla_\theta G(x;\theta^*)] = E_{x\sim p(x;\theta)}[\nabla_\theta G(x;\theta^*)]](https://s0.wp.com/latex.php?latex=E_%7Bx%5Csim+D%28x%29%7D%5B%5Cnabla_%5Ctheta+G%28x%3B%5Ctheta%5E%2A%29%5D+%3D+E_%7Bx%5Csim+p%28x%3B%5Ctheta%29%7D%5B%5Cnabla_%5Ctheta+G%28x%3B%5Ctheta%5E%2A%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
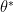 are the maximum likelihood parameters). Notice that this equation is a statement about the samples produced by the distribution
are the maximum likelihood parameters). Notice that this equation is a statement about the samples produced by the distribution 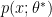 : the gradient of the goodness
: the gradient of the goodness 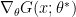 averaged over the data distribution
averaged over the data distribution 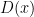 is equal to the same gradient averaged over the model’s distribution
is equal to the same gradient averaged over the model’s distribution 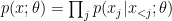 . Plugging it in into the objective of maximizing the average log likelihood of the data distribution
. Plugging it in into the objective of maximizing the average log likelihood of the data distribution ![\sum_j E_{D(x)}[\log p(x_j|x_{<j};\theta)]](https://s0.wp.com/latex.php?latex=%5Csum_j+E_%7BD%28x%29%7D%5B%5Clog+p%28x_j%7Cx_%7B%3Cj%7D%3B%5Ctheta%29%5D&bg=ffffff&fg=000&s=0&c=20201002) ,
, ‘s don’t share parameters for different
‘s don’t share parameters for different  ‘s, then the problems are truly independent and could be solved completely separately. So let’s say we found a
‘s, then the problems are truly independent and could be solved completely separately. So let’s say we found a ![E_{D(x_{<j})}[(E_{D(x_j|x_{<j})} [\log p(x_j|x_{<j};\theta^*)]](https://s0.wp.com/latex.php?latex=E_%7BD%28x_%7B%3Cj%7D%29%7D%5B%28E_%7BD%28x_j%7Cx_%7B%3Cj%7D%29%7D+%5B%5Clog+p%28x_j%7Cx_%7B%3Cj%7D%3B%5Ctheta%5E%2A%29%5D&bg=ffffff&fg=000&s=0&c=20201002) will be happy, which means that
will be happy, which means that  is similar, more or less, to
is similar, more or less, to 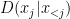 for
for  being sampled from
being sampled from  — which is the critical implied assumption made by the maximum likelihood objective applied to directed models. Why is it a problem when generating samples? It’s bad because this objective makes no “promises” about the behaviour of
— which is the critical implied assumption made by the maximum likelihood objective applied to directed models. Why is it a problem when generating samples? It’s bad because this objective makes no “promises” about the behaviour of 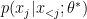 when
when 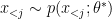 . It is easy to imagine that a
. It is easy to imagine that a 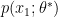 will be somewhat different from
will be somewhat different from 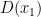 , and say that
, and say that  was sampled from
was sampled from 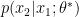 will freak out, having never seen anything like
will freak out, having never seen anything like  look even less like a sample from
look even less like a sample from 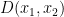 . Etc. This “chain reaction” will likely cause the directed model to produce worse-looking samples than an undirected model with a similar log probability.
. Etc. This “chain reaction” will likely cause the directed model to produce worse-looking samples than an undirected model with a similar log probability.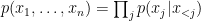 . Why won’t the above argument apply to an undirected model, which I claim is to be superior at sampling? An answer can be given, but it involves lots of handwaving.
. Why won’t the above argument apply to an undirected model, which I claim is to be superior at sampling? An answer can be given, but it involves lots of handwaving.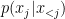 will share parameters in a very complicated way for different values of
will share parameters in a very complicated way for different values of ![E_{D(x_{<j})}[(E_{D(x_j|x_{<j})} [\log p(x_j|x_{<j})]](https://s0.wp.com/latex.php?latex=E_%7BD%28x_%7B%3Cj%7D%29%7D%5B%28E_%7BD%28x_j%7Cx_%7B%3Cj%7D%29%7D+%5B%5Clog+p%28x_j%7Cx_%7B%3Cj%7D%29%5D&bg=ffffff&fg=000&s=0&c=20201002) happy for all
happy for all  . This is why I assumed that the little conditionals don’t share parameters.
. This is why I assumed that the little conditionals don’t share parameters. and hidden binary vectors
and hidden binary vectors  . The intended analogy is that
. The intended analogy is that  , so
, so 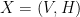 . The Boltzmann Machine defines a probability distribution over the configurations
. The Boltzmann Machine defines a probability distribution over the configurations 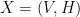 by the equation
by the equation
 yield different distributions
yield different distributions 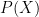 .
.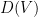 . For example,
. For example, ![L(W)=\displaystyle E_{D(V)} [\log P(V)]](https://s0.wp.com/latex.php?latex=L%28W%29%3D%5Cdisplaystyle+E_%7BD%28V%29%7D+%5B%5Clog+P%28V%29%5D&bg=ffffff&fg=000&s=0&c=20201002) ,
,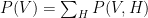 and
and ![E_{D(V)} [f(V)] = \sum_V D(V)f(V)](https://s0.wp.com/latex.php?latex=E_%7BD%28V%29%7D+%5Bf%28V%29%5D+%3D+%5Csum_V+D%28V%29f%28V%29&bg=ffffff&fg=000&s=0&c=20201002) . In other words, the goal of learning is to find a BM that assigns high log probability to the kind of data we typically observe in the world. This learning rule makes some intuitive sense, because negative log probability can be interpreted as a measure of surprise. So if our BM isn’t surprised by the real world, then it must be doing something sensible. It is hard to fully justify this learnnig objective, because a BM that’s not surprised by the world isn’t obviously useful for other tasks. But we’ll just accept this assumption and see where it leads us.
. In other words, the goal of learning is to find a BM that assigns high log probability to the kind of data we typically observe in the world. This learning rule makes some intuitive sense, because negative log probability can be interpreted as a measure of surprise. So if our BM isn’t surprised by the real world, then it must be doing something sensible. It is hard to fully justify this learnnig objective, because a BM that’s not surprised by the world isn’t obviously useful for other tasks. But we’ll just accept this assumption and see where it leads us.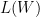 , which is something we can approach with gradient ascent: we’d iteratively compute the gradient
, which is something we can approach with gradient ascent: we’d iteratively compute the gradient 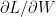 , and change
, and change  ,
, will be in a good place. And finally, here is the promised math:
will be in a good place. And finally, here is the promised math:![\partial L/\partial W_{ij} = E_{D(V)P(H|V)} [X_i X_j] - E_{P(V,H)}[X_i X_j]](https://s0.wp.com/latex.php?latex=%5Cpartial+L%2F%5Cpartial+W_%7Bij%7D+%3D+E_%7BD%28V%29P%28H%7CV%29%7D+%5BX_i+X_j%5D+-+E_%7BP%28V%2CH%29%7D%5BX_i+X_j%5D&bg=ffffff&fg=000&s=0&c=20201002) .
.![E_{P(V,H)}[X_i,X_j] = \sum_{(V,H)} P(V,H) X_i X_j](https://s0.wp.com/latex.php?latex=E_%7BP%28V%2CH%29%7D%5BX_i%2CX_j%5D+%3D+%5Csum_%7B%28V%2CH%29%7D+P%28V%2CH%29+X_i+X_j&bg=ffffff&fg=000&s=0&c=20201002) , and similarly for
, and similarly for 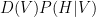 ) .
) .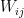 should change according to the difference of two averages: the average of the products
should change according to the difference of two averages: the average of the products 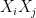 according to
according to 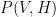 .
.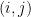 . So the connection will have little trouble detecting when the product is equal to 1 from local information (remember, our vectors live in
. So the connection will have little trouble detecting when the product is equal to 1 from local information (remember, our vectors live in 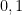 ).
).![E_{D(V)P(H|V)} [X_i X_j]](https://s0.wp.com/latex.php?latex=E_%7BD%28V%29P%28H%7CV%29%7D+%5BX_i+X_j%5D&bg=ffffff&fg=000&s=0&c=20201002) by taking the observed data from
by taking the observed data from ![E_{P(V,H)} [X_i X_j]](https://s0.wp.com/latex.php?latex=E_%7BP%28V%2CH%29%7D+%5BX_i+X_j%5D&bg=ffffff&fg=000&s=0&c=20201002) is computed by disconnecting the visible vector
is computed by disconnecting the visible vector 


